
系统扛不住并发别急着加 Redis——缓存用错了比没用更致命。本文拆解 L1 本地缓存 + L2 Redis 集群 + L3 CDN 三级架构设计,以及多租户数据隔离防越权的完整实战方案,附可运行代码示例与 3 种缓存病的防御 SOP。
系统扛不住并发别急着加 Redis——缓存用错了比没用更致命。本文拆解 L1 本地缓存 + L2 Redis 集群 + L3 CDN 三级架构设计,以及多租户数据隔离防越权的完整实战方案,附可运行代码示例与 3 种缓存病的防御 SOP。
Redis 加上了。系统崩得更彻底了。
3 分钟先看结论: SaaS 系统扛不住高并发别急着加 Redis——缓存雪崩、击穿、污染都能让数据库瞬间被打死。本文拆解 L1 本地缓存 + L2 Redis 集群 + L3 CDN 三级缓存架构,以及多租户数据隔离防越权的实战方案,附代码示例。
一、场景:加了 Redis,反而崩得更惨
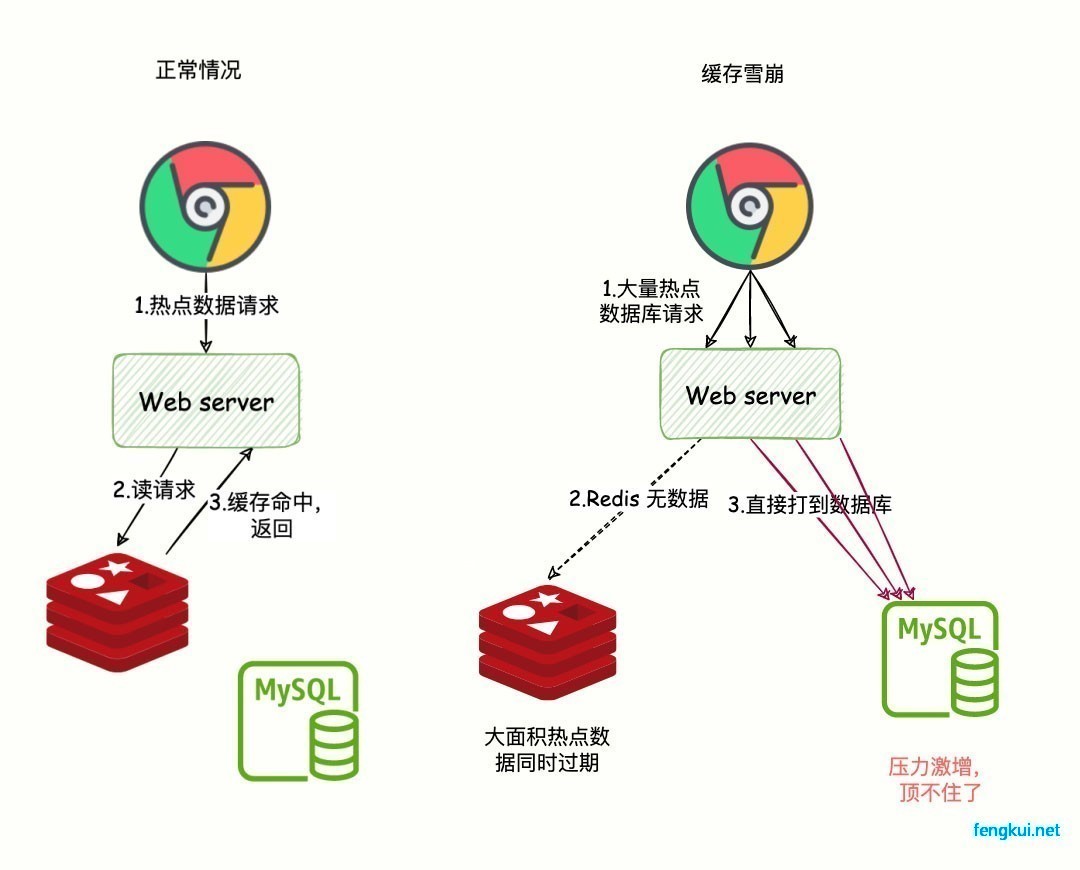
某多租户 SaaS 平台,业务增长到一定量级后开始出现慢查询。数据库响应时间拉长,用户端体验劣化。技术团队的第一反应——上 Redis,把热点数据缓存起来。
方案很快落地。热点查询的响应速度明显提升,团队松了口气。
直到某天整点时刻,监控面板上的数据库连接数突然直线拉满。
全站 502。
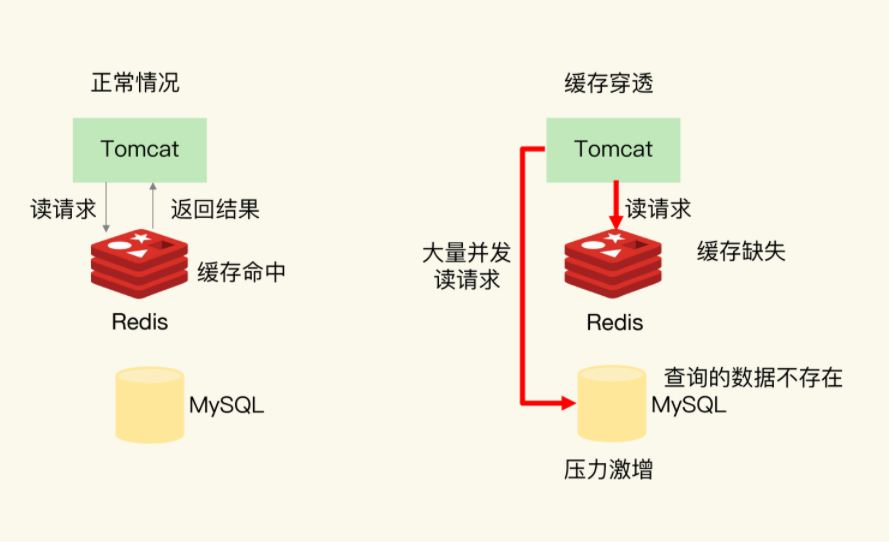
排查后发现:所有 Redis 缓存的 Key,TTL 统一设成了 3600 秒。整点一到,大批 Key 同时过期,几十万请求瞬间穿透缓存层直接砸向 MySQL。连接池在几秒内被打满,数据库直接躺平。
运维紧急重启 Redis。但 Redis 重启后是空的——没有预热机制,冷启动状态下又一波请求穿透到数据库。
崩溃、重启、再崩溃。反复折腾了 3 小时。
Redis 不是万能药。用错了,它就是一颗定时炸弹——而且爆炸时间你自己设的。
二、反共识:Redis 只是三级缓存的第二层
多数团队遇到性能瓶颈,脑子里只有一个词:加 Redis。
说白了,这个思路的问题不在于 Redis 本身,而在于把“缓存”等同于“Redis”。Redis 是分布式缓存的主力选项之一,但它只是完整缓存架构中的第二道防线。
一套能真正扛住高并发的 SaaS 缓存体系,至少需要三层协同:
用户请求
│
▼
┌──────────┐ 命中 → 直接返回
│ L3: CDN │──────────────────→ 响应
│ 边缘节点 │
└──────────┘
│ 未命中
▼
┌──────────┐ 命中 → 直接返回
│ L1: 本地 │──────────────────→ 响应
│ JVM 缓存 │
└──────────┘
│ 未命中
▼
┌──────────┐ 命中 → 直接返回(同时回写 L1)
│ L2: Redis │──────────────────→ 响应
│ Cluster │
└──────────┘
│ 未命中
▼
┌──────────┐
│ 数据库回源 │──→ 响应(同时回写 L2 → L1)
│ MySQL / PG│
└──────────┘
L1(本地缓存): 直接存在应用进程的 JVM 内存里,零网络开销,拦截最高频、最少变动的数据。
L2(Redis 集群): 多节点共享的分布式缓存,拦截中频业务数据。是主力,但必须防雪崩和击穿。
L3(CDN 边缘节点): 在用户最近的节点缓存静态资源,降低回源压力。
三层各守一段。只用 Redis,等于只建了第二道防线——第一道和第三道都是空的。
加 Redis 不是架构优化,是把鸡蛋换了个篮子。
三、L1 + L2 + L3 实战拆解
我们帮客户做过的架构审计里,缓存层出问题的项目占比极高。不是没用缓存,而是用法有病——以下逐层拆解,每层附带“常见病”和对应解法。
L1:本地缓存——拦截最高频、最少变的数据
本地缓存的核心价值是省掉网络 I/O。请求根本不出 JVM,直接从内存拿数据返回。
适用数据类型:极高频且极少修改的配置——租户 UI 主题色、权限菜单树、系统开关。这类数据一天可能只变一两次,但每个请求都要读。
常见的本地缓存方案包括 Caffeine、Guava Cache 等。以 Caffeine 为例——去掉它的技术包装,本质就是一个带过期策略和容量上限的内存 HashMap,只不过淘汰算法比手写的聪明得多。
以下是一段基础配置示例:
// ⚠️ 请以项目实际依赖版本为准(本示例基于 Caffeine 3.x + Java 17+) // 为什么用 Caffeine 而不是手写 ConcurrentHashMap? // → Caffeine 内置 W-TinyLfu 淘汰算法,命中率显著优于 LRU; // 手写缓存在并发场景下极易出现内存泄漏和竞态问题。 import com.github.benmanes.caffeine.cache.Cache; import com.github.benmanes.caffeine.cache.Caffeine; import java.time.Duration; Cache localCache = Caffeine.newBuilder() .maximumSize(10_000) // 最多缓存 1 万个 Key,超出按算法淘汰 .expireAfterWrite(Duration.ofMinutes(5)) // 写入 5 分钟后过期,防止数据陈旧 .recordStats() // 开启命中率统计,上线后用于调优 .build();
L1 的坑: 多节点部署时,各节点的本地缓存是独立的。如果缓存的是频繁变动的数据(比如用户余额),节点 A 更新了但节点 B 还是旧值——数据不一致。所以 L1 只适合存“改了也不怕晚几分钟生效”的配置类数据。动态业务数据交给 L2。
L2:Redis 集群——中频业务数据的主力缓存
适用数据类型:用户余额快照、订单状态、会话信息——读取频率高、需要多节点共享、但不像配置那样几乎不变。
L2 是主力战场,也是出问题最多的一层。两种“缓存病”需要重点防御:
缓存病 ①:雪崩。 用一个画面理解它——高速公路上所有车的油同时烧完,全部抛锚在路上,后面的车全堵死。对应到系统:大批缓存 Key 在同一时刻过期,海量请求同时穿透到数据库,数据库瞬间过载。
开头那个场景就是典型的雪崩。
解法:TTL 加随机抖动。不让所有 Key 同时过期,而是在基准 TTL 上加一个随机偏移量,把过期时间打散。
// ⚠️ 请以项目实际依赖版本为准 // 为什么要加随机抖动而不是直接用固定 TTL? // → 固定 TTL = 所有 Key 同时过期 = 雪崩; // 随机抖动把过期时间打散到一个区间内,削平穿透峰值。 import java.util.concurrent.ThreadLocalRandom; long baseTtlSeconds = 3600L; // 基准过期时间:1 小时 long jitterSeconds = 600L; // 抖动范围:0~600 秒 long finalTtl = baseTtlSeconds + ThreadLocalRandom.current().nextLong(jitterSeconds); // 实际 TTL 在 3600~4200 秒之间随机分布 // 即使同一批写入的 Key,过期时间也不会撞在同一秒
缓存病 ②:击穿。 换个说法:某个超级热点 Key 过期的瞬间,大量并发请求同时发现“缓存里没有了”,全部涌向数据库去查同一条数据。数据库被同一个查询的几千个副本同时击中。
解法:互斥锁(singleflight 模式)。第一个发现缓存失效的请求去数据库查并回写缓存,其余请求等着拿结果,而不是每个都去查一遍。具体实现可以用分布式锁(如 Redis 的 SET NX EX)或应用层的 singleflight 组件。
L2 的坑: 单节点 Redis 本身就是单点故障。生产环境建议使用 Redis Sentinel 或 Redis Cluster 模式。常见的托管方案(如各云厂商的 Redis 服务)通常已内置高可用,但具体 SLA 以厂商文档为准。
L3:CDN——为什么更新了系统,用户看到的还是旧页面?
这个问题在技术支持群里反复出现。
开发团队明明已经发布了新版本,但用户刷新页面看到的还是旧样式、旧脚本。清了浏览器缓存才正常——但你不可能让几十万用户都去清缓存。
根因不在浏览器,在 CDN 缓存策略。
CDN 节点缓存了旧版本的静态资源(JS / CSS / 图片),而新版本的文件名和旧版本一样,CDN 认为“没变化”就继续返回旧文件。——这里有个容易被忽略的细节:CDN 判断“要不要用缓存”主要看两个东西:文件 URL 是否变了,以及 HTTP 响应头里的 Cache-Control 怎么配的。
解法是两步:
第一,静态资源 URL 加版本哈希。把 app.js 变成 app.js?v=abc123,每次构建生成新哈希,CDN 看到 URL 变了就会重新拉取。
第二,配置 Cache-Control 响应头。对频繁变动的资源设短缓存或 no-cache(每次都向源站验证是否有更新),对极少变动的资源设长缓存。
⚠️ 缓存策略需结合具体业务场景和数据特征,上述框架为方向性参考。缓存中间件版本持续迭代,API 和最佳实践可能变化。代码示例基于撰写时的常见版本,请以项目实际依赖为准。Redis Cluster 多节点部署成本显著高于单节点,应按业务规模评估。
缓存只是第二道防线——底层的多租户数据库拆分没做对,缓存加再多也白搭
四、多租户数据隔离:一个 API 扒光竞争对手数据的惨案
在多租户系统里,性能差顶多被骂,数据串号直接关门。
我们做过的安全审计里,有一类漏洞出现频率高得令人不安:在接口 URL 或请求参数中修改 tenant_id,就能看到另一家租户的全部业务数据。
安全审计中的典型发现是这样的:某多租户 SaaS 系统的订单查询接口,URL 中包含 tenant_id=1001。审计人员将参数改为 tenant_id=1002,系统返回了另一家公司的完整订单列表。没有任何拦截,没有任何告警。
这类漏洞在安全领域被称为 BOLA(Broken Object Level Authorization)或 IDOR(Insecure Direct Object Reference)——名字听起来很学术,翻译成人话就是“你家的门牌号被人改了一个数字,就进了邻居家,而且门没锁”。它被主流安全组织列为高危漏洞类型。
根因只有一个:后端只校验了“用户是否登录”,没有校验“这个用户是否属于他声称的那个租户”。
解法:构建 Tenant Context
Tenant Context,直白地说,就是给每个请求贴一张“身份标签”——从请求进入系统的第一步就确认“你是哪个租户的人”,然后在整条处理链路上强制携带这张标签,每一步都核对。
核心原则:绝不信任前端传来的 tenant_id。
正确做法是从 JWT Token 中解析真实的租户 ID。JWT——用更直接的说法:它是一张加密的“电子工牌”,用户登录时由服务端签发,里面写着“这个人属于哪个租户”。因为有签名保护,前端改不了。
解析出的租户 ID 放入 ThreadLocal。ThreadLocal 的作用类似于一条流水线上每个工位都能看到的“工单夹”——这个请求在当前线程里走到哪一步,都能从工单夹里取出租户 ID 来核对权限。
以下是一个拦截器的基础实现:
// ⚠️ 请以项目实际依赖版本为准(本示例基于 Spring Boot 3.x / Jakarta EE)
// 为什么用拦截器而不是在每个 Controller 里手动校验?
// → 拦截器在请求进入业务逻辑之前统一处理,避免任何一个接口遗漏校验;
// 手动校验依赖开发者记忆,漏一个接口就是一个越权入口。
import jakarta.servlet.http.HttpServletRequest;
import jakarta.servlet.http.HttpServletResponse;
import org.springframework.web.servlet.HandlerInterceptor;
public class TenantInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request,
HttpServletResponse response,
Object handler) throws Exception {
// 第 1 步:从 JWT Token 中解析租户 ID(而非从 URL 参数中读取)
String token = request.getHeader("Authorization");
String tenantId = JwtUtils.extractTenantId(token); // 自行实现的 JWT 解析工具
if (tenantId == null) {
response.setStatus(403); // 403 Forbidden:无法确认租户身份,直接拒绝
return false;
}
// 第 2 步:写入 ThreadLocal,后续所有业务逻辑从这里取租户 ID
TenantContextHolder.set(tenantId);
return true;
}
@Override
public void afterCompletion(HttpServletRequest request,
HttpServletResponse response,
Object handler, Exception ex) {
// 第 3 步:请求结束后必须清理 ThreadLocal,防止线程复用导致租户串号
TenantContextHolder.clear();
}
}最后一行 TenantContextHolder.clear() 极其关键。线程池环境下线程会被复用,如果不清理,下一个请求可能继承上一个请求的租户 ID——这本身就是一种数据越权。
大量血泪案例证明,多租户系统的数据越权漏洞,绝大多数不是因为“没想到”,而是因为“漏了一个接口”或“忘了清理 ThreadLocal”。一个接口的遗漏,就足以让整套隔离体系形同虚设。
⚠️ 租户隔离方案需结合具体技术栈和业务模型,上述为方向性框架。安全威胁持续演进,隔离机制应定期接受渗透测试。Spring Boot / Jakarta EE 版本迭代可能影响拦截器实现方式。完善的租户隔离测试体系需要持续投入自动化测试资源。
五、数据层安全:敏感数据绝不裸奔
租户隔离解决了“谁能看谁的数据”。但还有一个问题:数据本身在存储和传输过程中,是不是明文?
把账算到桌面上你就明白了:即使接口层的隔离做得滴水不漏,如果数据库里的身份证号、手机号、银行卡号全是明文存储,一旦数据库被拖或内部人员越权查询,隔离等于白做。
三道防线,逐层加固:
第一道:字段级加密。 敏感字段在写入数据库前必须加密。常见做法是使用 KMS(密钥管理服务)统一管理加密密钥——剥掉技术外壳看本质,KMS 就是一个专门保管钥匙的保险柜,应用系统需要加密或解密时向它申请,密钥本身永远不离开保险柜。加密算法方面,AES-256 是当前行业基线——顺带提一句,256 这个数字指的是密钥长度,数字越大暴力破解的计算量越大,目前被认为在可预见的未来足够安全。常见的企业级密钥管理方案包括 HashiCorp Vault、各云厂商的 KMS 服务等。
铁律:敏感数据严禁明文存入 Redis 缓存。Redis 默认不加密,且在部分部署场景下缺乏细粒度访问控制,一旦内网被渗透,缓存中的明文数据是最容易被批量读取的目标。
第二道:操作留痕。 API 网关层集成 WAF(Web 应用防火墙)——用日常语言说,WAF 就是 API 的安检门,所有进出的请求都要过一遍,发现 SQL 注入、XSS 等攻击特征直接拦截。核心业务操作(数据导出、权限变更、租户配置修改)必须记录审计日志,同步到日志分析平台。常见的日志分析平台包括 ELK(Elasticsearch + Logstash + Kibana)等——可以把它理解为一套“监控录像回放系统”,出事后能按时间线还原谁在什么时候做了什么操作。
第三道:上线前跑隔离测试。 每次大版本发布前,必须执行一轮租户数据隔离测试——用 A 租户的账号请求 B 租户的资源,确认系统返回 403 Forbidden 而非 B 租户的真实数据。这不是可选项,是上线前的必过门禁。
测试用例的设计方向:覆盖所有包含 tenant_id 的接口,逐一验证跨租户请求是否被正确拦截。建议将这类测试纳入 CI / CD 流水线自动执行,而非依赖手动测试——手动测试的覆盖率取决于测试人员的记忆力,而接口数量会随业务迭代持续增长。
⚠️ 加密和审计方案需结合具体合规要求和技术栈。加密算法强度标准持续演进,应定期评估。WAF 规则和日志平台版本持续更新。企业级 KMS 和日志平台有显著的许可和运维成本。
六、收口:两条生命线,一条都不能断
做这行见过的系统不算少。上线第一周就出事的,几乎都栽在同一个模式里:要么缓存层设计粗糙,流量一上来数据库直接被打穿;要么租户隔离只做了“能用”没做到“安全”,上线后被安全审计扫出越权漏洞,紧急下线修复,品牌信任归零。
高并发 SaaS 系统的两条生命线——性能靠三级缓存,安全靠租户隔离。
缓存设计错了,系统会崩。隔离没做好,公司会关门。架构设计对了,部署到香港还有哪些坑?
这两件事不是上线后再补的“优化项”,而是必须在架构设计阶段就写进基因里的东西。L1 拦什么、L2 防什么、L3 管什么、Tenant Context 怎么传递、敏感字段怎么加密、上线前跑什么测试——每一项都应该在第一行代码写下之前就有明确答案。
坑都知道了,东南亚千万级场景下具体怎么优化?如果你的 SaaS 系统正在遭遇高并发瓶颈,或者不确定多租户隔离是否存在越权漏洞,可以探讨一次轻量级的架构方向梳理,过一遍缓存层级、隔离机制和加密策略的优先级。
常见问题
Q1:L1 本地缓存和 L2 Redis 缓存到底该存什么?
判断标准是两个维度:变动频率和共享需求。
L1 存“极高频读取 + 极少变动 + 不需要跨节点共享”的数据——典型如租户 UI 主题配置、权限菜单树、系统功能开关。这类数据一天可能只改一两次,但每个请求都要读,放 L1 省掉网络往返。
L2 存“中高频读取 + 有变动 + 需要多节点共享”的数据——典型如用户余额快照、订单状态、会话信息。这类数据多个应用节点都要读到同一份,必须走分布式缓存。
反面场景:某团队把用户余额放进 L1 本地缓存,部署了 4 个应用节点。用户在节点 A 上充值成功,余额更新了;但下一个请求被负载均衡分配到节点 B,读到的还是旧余额。用户看到“钱没到账”,投诉量直接飙升。余额这类数据,只能放 L2。
Q2:TTL 设多长合适?怎么防止缓存雪崩?
没有“万能 TTL”。核心原则是:TTL 应该匹配数据的业务更新频率,而不是拍脑袋定一个整数。
配置类数据(几乎不变):TTL 可以设较长,比如数十分钟到数小时。业务状态数据(分钟级变动):TTL 应该短得多,通常在秒级到分钟级。
防雪崩的关键动作是 TTL 加随机抖动——在基准 TTL 上叠加一个随机偏移量,让同一批写入的 Key 不在同一秒过期。文中的代码示例展示了 base + ThreadLocalRandom.current().nextLong(jitter) 的模式。
反面教训:某系统所有缓存 Key 的 TTL 统一设为 3600 秒,每到整点就出现一波数据库连接数飙升。团队排查了三次才定位到原因——因为“整点过期”这个现象只在流量足够大时才会触发明显故障,低峰期根本看不出来。
Q3:多租户系统怎么测试数据隔离有没有漏洞?
最直接的方式:用 A 租户的合法登录凭证,尝试请求 B 租户的资源,验证系统是否返回 403 Forbidden。
这个测试必须覆盖所有包含租户标识的接口——不只是“核心接口”,而是全部。安全审计中反复出现的情况是:主流程接口(订单查询、用户管理)做了隔离校验,但边缘接口(导出报表、操作日志查询、配置项读取)漏掉了。攻击面往往就在这些“不起眼”的接口上。
建议将隔离测试写成自动化用例,纳入 CI / CD 流水线。每次代码合并自动跑一遍,新增接口如果没有配套的隔离测试用例则构建失败。靠人记住“哪些接口要测”是不可持续的。
Q4:敏感数据放 Redis 缓存安全吗?
默认情况下,不安全。
Redis 的设计目标是高性能读写,而非数据安全。在部分部署场景下,Redis 实例没有启用访问认证,也没有加密传输——这意味着同一内网内的任何有权限的机器都可以直接连接并读取全部缓存数据。
反面场景:某团队为了提升查询速度,把用户手机号和身份证号的明文缓存到 Redis。内网渗透测试中,安全团队在几分钟内就批量导出了全部缓存内容。事后复盘发现 Redis 实例既没有设密码,也没有开启 TLS 加密传输。
如果业务场景确实需要在 Redis 中缓存敏感字段,至少做到三点:启用访问认证(requirepass)、开启 TLS 加密传输、敏感字段在写入 Redis 前先做字段级加密(而非明文写入)。但更优的方向是:评估是否真的需要缓存这些字段——如果只是为了减少数据库查询,是否可以只缓存脱敏后的摘要信息而非原始值。