
沙箱跑通≠生产环境稳——沙箱只考"语法",生产环境考"拓扑"和"负载"。WAF 误杀、429 限流、跨国 DNS 解析这 3 座大山,才是上线之夜真正掀翻平台的元凶。这份指南帮你看清生产环境的隐形障碍。
沙箱跑通 ≠ 生产环境稳——沙箱只考“语法”,生产环境考“拓扑”和“负载”。WAF 误杀、429 限流、跨国 DNS 解析这 3 座大山,才是上线之夜真正掀翻平台的元凶。这份指南帮你看清生产环境的隐形障碍。
凌晨 3 点,告警群炸锅。
技术负责人盯着监控大屏,整个人是懵的——沙箱跑了半个月零报错,老板群里香槟表情包还没散,怎么切到正式域名就这样了?
3 分钟先看结论: 沙箱跑通 ≠ 生产环境稳——沙箱只考“语法”,生产环境考“拓扑”和“负载”。WAF 误杀、429 限流、跨国 DNS 解析这 3 座大山,才是上线之夜真正掀翻平台的元凶。
一、上线之夜的“薛定谔报错”:一个匿名复盘
我们排过的上线事故里,这个剧本几乎逐字逐句重演——
铺垫: 沙箱测试跑了半个月,零报错。技术团队连夜把所有用例又过了一遍,依然全绿。老板已经在群里发“准备开香槟”。
突变: 切到正式域名上线,前 10 分钟一切正常——玩家进得来、游戏跑得动、回调也收得到。第 11 分钟开始,请求超时、回调收不到的告警开始刷屏,一分钟比一分钟密。
混乱: 技术团队抓起本地环境重测一遍,正常;用 Postman 直接调线上接口,也正常;可生产环境的业务请求就是不通。报错毫无规律——这一笔通、下一笔不通;这台服务器通、那台服务器不通。
像极了那只“既死又活”的薛定谔的猫。
我们见过太多团队在这个环节通宵排障——最后发现,根本不是代码的锅。是被自己买的安全防火墙、自己用的 CDN、甚至自己服务器的 DNS 给坑了。
二、反共识洞察:沙箱骗了你什么?
这件事的根,不在哪一行代码,在认知层。
市场普遍把沙箱当成生产环境的“缩小版”——以为沙箱跑通了,切到生产环境只要换个域名、换个密钥就行。真实情况是——沙箱其实是一个“温室”,它故意屏蔽了真实互联网的复杂性。
我们排过的上线事故里反复确认过:沙箱和生产环境,根本不是同一份考卷。把两份卷子摊开比对,差异立刻清楚——
维度 1|流量特征对比
- 沙箱: 单线程测试,参数都是你自己造的,节奏由你控制——你按一下回车,它跑一笔
- 生产环境: 高并发洪峰,玩家集中涌入的瞬间不由你——开服第一分钟可能就是平时压力的几十倍
维度 2|网络链路对比
- 沙箱: 点对点直连,中间没有任何代理,请求直接到达
- 生产环境: 要经过 CDN 加速 → WAF 安全检测 → 负载均衡 → 后端这 4 层代理——每一层都可能“动手脚”,每一层都有可能把你的回调拦下来
维度 3|容错机制对比
- 沙箱: 报错了你自己看,可以慢慢调,没人催
- 生产环境: 报错了玩家在投诉、老板在催、财务在追问——容错窗口几乎是零
把这三个维度叠起来你就明白了——
不要用沙箱的成功来背书生产环境的稳定。 这两份考卷根本不是同一张。沙箱考的是“你有没有把代码写对”,生产环境考的是“你有没有把架构搭对”。代码对了不等于架构对——这是 2 道独立的关卡。
“沙箱考代码写对没,生产环境考架构搭对没。”
三、排障录:生产环境的 3 座隐形大山
把方向校准之后,进入实战。上线之夜真正把平台掀翻的,几乎都集中在下面这 3 座大山——
大山 1|WAF 误杀回调
WAF 说白了,就是你网站门口请的保安——但这个保安经常把厂方发来的正常回调当成黑客攻击,直接拦在门外不让进。
症状:
- 沙箱回调全通,生产环境回调要么收不到,要么收到的是 HTTP 403 / 503
- 厂方那边显示请求已发出,你这边日志连入站记录都没有——请求根本没进到你的业务层
根因:
- 主流云 WAF(如 Cloudflare、阿里云 WAF 等)默认开启了一批“通用拦截规则”
- 这些规则按“特征匹配”工作——厂方回调中的某些字段(特殊参数、长 Token、JSON 嵌套结构)可能恰好命中默认拦截规则
- 你的回调被当成“疑似攻击”丢了,但 WAF 日志和业务日志是分开的——业务团队看不到,安全团队不知道
解决动作:
- 把厂方回调 IP 段加入 WAF 白名单(最直接、最有效)
- 或:为回调路径单独配置“规则豁免”,关闭通用拦截
- 或:调整 WAF 误杀率阈值——业界经验值通常落在千分之三到千分之五区间,过低则容易误杀
老炮判断: WAF 是上线后第一个该排查的地方——它不是不工作,是工作得太尽职。保安误把家人当贼,本质上不是保安坏,是你忘了告诉它“家人长什么样”。
解决 WAF 误杀只是放行了厂方——放行之后,如何确保进来的真的是厂方而不是冒充者?这里有一份回调防伪造的 3 道底线
大山 2|429 限流
429 这个状态码翻译过来就是“请慢点,太挤了”——厂方在告诉你:你的请求速度超过我允许的阈值,再快下去我就不接你电话了。
症状:
- 玩家集中上线的瞬间,请求大量返回 HTTP 429
- 部分场景下,厂方会直接封禁你的 IP 一段时间作为惩罚——封禁期间,你连“请慢点”都收不到,直接是连接超时
根因:
- 厂方对正式接口有严格的频率限制,业界经验通常在每秒数百次量级,具体阈值以厂方文档为准
- 瞬时并发超标 → 触发限流 → 部分平台还会触发 IP 封禁惩罚——这是双重打击
解决动作:
- 引入消息队列(如 Redis 队列、RabbitMQ 等通用方案)做“削峰填谷”——把瞬时洪峰先存进队列,按厂方能接受的速度放出去
- 设置合理的客户端限速,主动控制每秒请求数低于厂方阈值
- ⚠️ 严禁配置“失败立即重试”——这是雪崩根源(下一节会详细推演)
老炮判断: 限流不是厂方在为难你,是厂方在保护自己——也是在保护你。一个能让所有人随便发请求的接口,活不过开服第一天。
大山 3|跨国 DNS 解析延迟
为什么本地 Ping 厂方接口飞快,线上服务器一发请求就超时?
为什么同一段代码、同一个域名,你的香港服务器秒回,你的北美服务器就超时?
为什么你和同行用的是同一家厂方,他那边稳如老狗,你这边天天告警?
因为 DNS 解析根本不是“全球一份答案”——不同节点解析同一个域名,走的路径、命中的边缘节点、甚至最终的 IP 都可能不一样。你以为你和厂方“通过同一根管子”说话,实际上每台服务器走的管子都不同。
DNS 污染换句话讲,就是你电脑通讯录里存的厂方电话号码,在不同地区的电信局那里可能是不同的号码——有些地区给你的号码是对的,有些地区给你的号码是过期的、甚至是被恶意改掉的。
具体排查动作:
- 在生产服务器上用 dig / nslookup 查看实际解析到的 IP
- 对比厂方文档给出的官方 IP,看是否一致
- 不一致 → 配置本地 hosts 文件强制指定,或购买专属 DNS 解析服务(如云厂商的私有 DNS)
- 同时检查跨国链路质量(如 mtr 命令查看丢包节点)
老炮判断: DNS 这个坑最阴——因为它跟你的代码、你的 WAF、你的限流策略全都无关,完全藏在“底层网络”里。排障排到怀疑人生的时候,先 dig 一下,往往一秒钟就破案了。
四、数据化推演:一个 429 报错引发的雪崩
光看 3 座大山还不够。
真正可怕的,是大山之间的连锁反应——一个 429 报错,怎么就把整个平台拖进了假死状态。把账算到桌面上你就明白了,这条灾难链条的传导速度,远超一般技术团队的直觉。
灾难链条的 4 幕剧
第一幕|动作: 玩家集中上线的瞬间,大量“获取余额”请求同时涌向厂方接口——这是一波瞬时高并发洪峰。
第二幕|触发: 厂方接口达到限速阈值,大量请求被返回 HTTP 429(请慢点,太挤了)。
第三幕|恶化(核心雪崩点):
技术团队当初为了“容错”,在客户端写了“失败自动重试 N 次”的逻辑——于是每一个 429 错误,都立刻变成了数倍的重试请求。
原本的高并发洪峰,被自己的重试机制数倍放大。厂方那边看到的不是“高并发”,而是“看起来像 DDoS 的恶意请求”——IP 被自动封禁。
第四幕|结局:
封禁期间,所有请求堵在客户端连接池里等待重试,数据库连接池被打满,业务线程全部阻塞——整个包网平台进入“看似在跑、实际全卡”的假死状态。
玩家这边的体验是:界面转圈、余额不显示、提现按钮失灵。
一次 429,引发了整个平台的雪崩。
老炮解法:蓄水池 + 退避
削峰填谷通俗讲,就是在你的应用和厂方接口之间,加一个“蓄水池”——高峰期把请求先存进池子里,按厂方能接受的速度慢慢放出去;低峰期再把池子清空。池子越大,扛过的洪峰越大。
动作建议:
- 引入消息队列(如 Redis 队列、RabbitMQ、Kafka 等通用方案)做缓冲层
- 客户端主动限速,控制每秒发出的请求数低于厂方阈值
- 失败重试必须配合“指数退避”(Exponential Backoff)——不是立即重试,而是每次重试前等待时间翻倍(1 秒 → 2 秒 → 4 秒 → 8 秒……)
- ⛔ 严禁“无脑重试”“立即重试”——这是雪崩的根源
老炮判断: 高并发场景里,“失败重试”不是好心,是凶器——除非配合限流和退避,否则你写的不是容错,是给自己平台发起的 DDoS 攻击。
“没有缓冲的失败重试,是自己给自己发起的 DDoS。”
五、上线前夜:从内网穿透到灰度发布的 3 步走
讲完原理,给你一份能立刻用的上线过渡 Checklist。
下面这 3 步走,是把“上线之夜的薛定谔报错”概率压到最低的标准动作——不是花架子流程,是用自家的脚本把所有可能崩的地方先崩一遍。
步骤 1|内网穿透调试(先小范围验证真实链路)
内网穿透实际上就是,在你家路由器和外部互联网之间打一条临时小通道——让外面的服务器(厂方接口)能直接调到你本地正在调试的代码,而不需要先部署到正式服务器上。
操作描述:
- 用通用内网穿透工具(如 ngrok、frp 等公开方案),把本地开发环境暴露成一个临时公网地址
- 用这个临时地址当回调地址,调一次厂方正式生产接口(不是沙箱接口)
- 看真实生产环境下的链路能不能跑通
通过标准:
- 跑通 → 说明你的代码逻辑能扛住“真实生产链路”的复杂度
- 不通 → 在切正式服务器之前,就把问题暴露出来了
老炮判断: 内网穿透是“低成本试错”的最佳方式——不用动正式服务器、不用改 DNS、不用配 WAF,搭起来快,问题立马露馅。
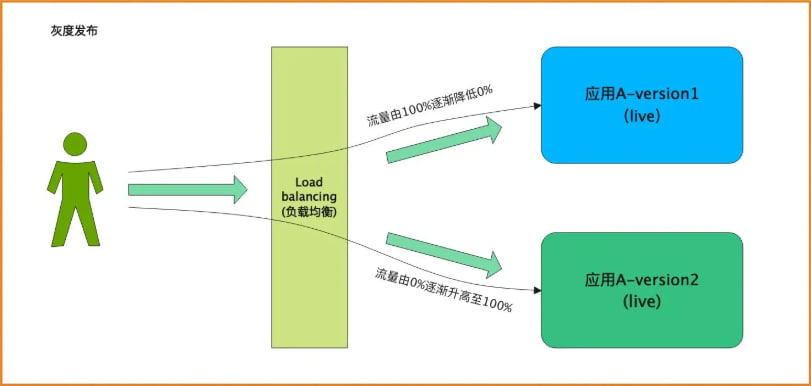
步骤 2|白名单灰度(先放一小撮内部 IP 进生产)
操作描述:
- 在正式生产环境部署完成后,先在 WAF / 网关层只放行“公司内部 IP”
- 用内部团队跑一遍完整的资金流:充值 → 下注 → 中奖回调 → 余额更新 → 提现
- 跑通后再逐步放开 IP 限制
通过标准:
- 内部资金流全链路跑通 → 才有资格开放给真实玩家
- 任何一个环节卡住 → 修完再灰度,绝不直接全量
老炮判断: 灰度发布的本质,是把“雪崩”限定在“可控范围”里——就算崩了,崩的也只是你公司内部几个测试号,不是真金白银的玩家账户。
步骤 3|压测摸底(先找到 429 的临界点)
操作描述:
- 用通用压测工具(如 wrk、JMeter、Locust 等公开方案),模拟阶梯式并发压力
- 从低并发开始逐步加压,观察请求成功率、响应时间、429 出现的临界点
- 找到“厂方接口能扛住的安全水位”,把客户端限速设在这个水位之下
通过标准:
- 找到 429 临界点 → 配置客户端限速 + 削峰队列
- 没找到就直接上线 → 等于把“找临界点”的工作交给真实玩家来做
老炮判断: 压测不是“走流程”——是用自己的脚本,把所有可能崩的地方先崩一遍。宁可上线前自己崩,不要上线后让玩家替你崩。
收口: 这 3 步走完,上线之夜的“薛定谔报错”会少一大半。
但安全是动态的——业务量上去之后,老问题会以新形式出现。压测和灰度不是一次性动作,是每次大版本更新前都该重跑的标准流程。
六、决策收口与下一步
我们常说,沙箱通了只算完成了开头那一小段——真正的硬仗,全在应对真实互联网的残酷环境。
通宵排障的那一夜很难熬,但更难熬的是事后那场复盘——会议室里没人说话,对账表上的窟窿明明白白。商业铁律就在于:不要拿玩家的真金白银,去当生产环境的“测试数据”。
“上线前能崩的地方,请在自家压测里崩;不要等上线后让玩家替你崩。”
上线前那一晚多花的几个小时压测、多走的一遍灰度,比上线后通宵 N 天回滚要划算得多。这笔账算到桌面上,每个老板都该看得明白——压测和灰度不是技术团队的“加班负担”,是平台老板的“保险费”。
如果你正在准备 PG / PP / JILI 等主流 API 的上线部署,或者线上环境频繁出现偶发性断连、回调丢失,可以预约一次轻量级的【接入合规评估】——我们会帮你过一遍上面的 3 座大山,再跑一遍 3 步走的上线思路,给一份方向性的排障建议。
评估不替您接管服务器,思路你拿走自己用就行。
搞定线上排障,意味着技术对接正式收尾——但要让平台长期稳定盈利,建议重新审视这份 API 对接全局地图
七、FAQ:5 个最常被问的实战问题
Q1:沙箱跑了半个月零报错,是不是说明代码完全没问题了?
A:只能说明代码在“温室”里没问题。沙箱屏蔽了真实互联网的复杂性——没有 WAF 拦截、没有 CDN 转发、没有跨国 DNS 漂移、没有真实玩家洪峰。这些东西全在生产环境等着你。沙箱通过,只是拿到了“可以上线尝试”的入场券,不是“保证不崩”的免死金牌。
Q2:上线后部分回调收不到,技术说是网络抖动重试就行——靠谱吗?
A:不靠谱,而且很危险。“网络抖动”是排障最偷懒的借口——绝大多数“网络抖动”背后,其实是 WAF 误杀、限流触发或 DNS 解析异常。如果不查清根因就配重试,等业务量上去那天,重试机制会把小问题放大成雪崩。先 dig、先看 WAF 日志、先抓 429 频率,再谈重试。
Q3:买了 WAF 反而把厂方回调拦了,是不是该把 WAF 关掉?
A:千万别。关 WAF 等于把家门拆了防保安误杀。正确动作是把厂方 IP 段加白名单、为回调路径单独配规则豁免——让 WAF 知道“这几个客人是自己人”。WAF 该工作的时候得工作,回调安全的另一道防线(签名校验、幂等性)才能真正发挥作用。
Q4:跨国服务器和厂方接口经常超时,是不是必须换机房?
A:换机房是最后的选择,先排查 DNS 和链路质量。生产服务器 dig 一下,看解析到的 IP 对不对;mtr 一下,看丢包卡在哪一跳。很多“超时”问题,配个 hosts 文件强制指定 IP 就解决了,根本不用动机房。机房迁移的成本和风险都很高,不到万不得已不要走这一步。
Q5:压测要做到什么程度才算合格?是不是越极限越好?
A:不是越极限越好,是要找到“厂方接口的安全水位”——也就是 429 开始出现的临界点。压测的目的不是把厂方接口打挂,是知道自己能跑多快、该把限速设在哪里。把客户端限速设在临界点之下、配好削峰队列、配好指数退避——这三件套齐了,压测就算合格。每次大版本更新前,再重跑一遍。